


































![Kong Interview Preparation Guide [2025]](https://www.devopstraininginstitute.com/blog/uploads/images/202509/image_430x256_68dbb95326997.jpg)















12 Kubernetes Job Scheduling Techniques
Master the intricate world of Kubernetes job scheduling with this detailed guide to 12 essential techniques. Learn how to control precisely where your Pods land using resource management, affinity and anti-affinity rules, taints and tolerations, and quality of service classes. Optimal scheduling is vital for cluster efficiency, cost management, and application resilience. This post demystifies everything from basic resource requests to advanced priority preemption and custom schedulers, providing beginners and seasoned engineers with the knowledge to optimize workload placement across diverse worker nodes for performance, fault tolerance, and efficient resource utilization within any system.
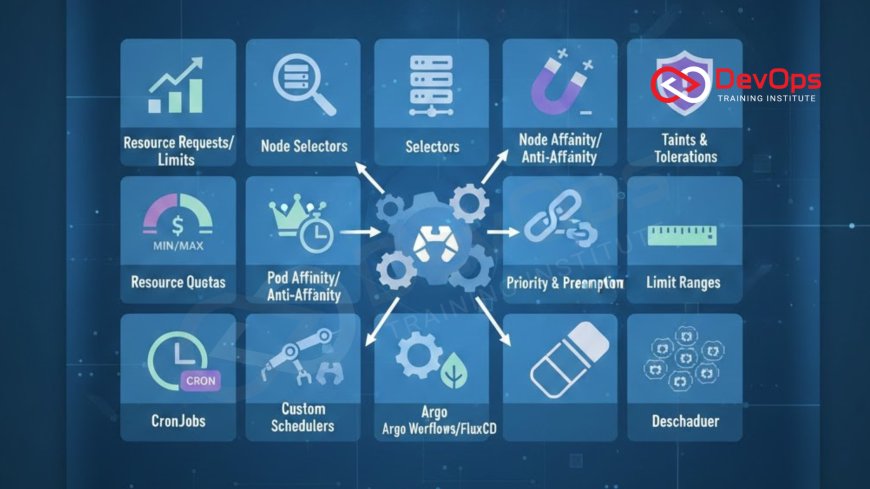
Introduction to Intelligent Pod Placement
Kubernetes is fundamentally a resource orchestration and scheduling platform. When a user creates a new workload, such as a Job or a Deployment, the Kubernetes scheduler is responsible for deciding which worker node is the best fit for the resulting Pods. While the default scheduler is highly effective for general-purpose workloads, relying solely on it is rarely optimal for complex production environments. Intelligent job scheduling is the art and science of guiding the scheduler to place Pods strategically based on criteria far more nuanced than simple resource availability. This control is crucial for managing costs, ensuring high availability, meeting strict latency requirements, and adhering to licensing or compliance rules.
The core challenge in a Kubernetes cluster is balancing two often conflicting priorities: efficiency and resilience. Efficiency demands packing Pods tightly onto fewer servers to save on infrastructure costs, while resilience requires spreading Pods across failure domains (like availability zones) to ensure that a single failure does not take down an entire service. The various scheduling techniques provided by Kubernetes offer the necessary levers to manage this delicate balance. By combining these techniques, operators can build bespoke scheduling policies that reflect the precise needs of their applications and the constraints of their infrastructure.
Understanding these 12 techniques allows operators to move beyond reactive troubleshooting and into proactive cluster optimization. Poor scheduling leads to resource waste, performance degradation due to co-located noisy neighbors, and unnecessary service downtime. Mastering these configuration options turns a basic Kubernetes cluster into a highly tuned, efficient, and resilient execution environment, making the scheduler a key component in the overall success of the system architecture.
Technique Resource Requests and Limits
The foundation of all scheduling decisions starts with resource requests and limits. A Resource Request is the guaranteed minimum amount of CPU and memory a Pod needs to run. The scheduler uses this value to determine if a node has sufficient available resources to place the Pod. Without a request, the scheduler assumes a minimal requirement, which can lead to oversubscription and resource contention. Setting an accurate request is the most fundamental step in guaranteeing a Pod’s stability and ensuring fair resource allocation across the cluster.
Resource Limits, conversely, define the maximum amount of CPU and memory a container can consume. If a container attempts to consume CPU beyond its limit, the container runtime throttles it. If it consumes memory beyond its limit, the Pod is terminated, often resulting in an Out-of-Memory (OOM) error. Requests and Limits are also inextricably linked to the Quality of Service (QoS) class assigned to a Pod, dictating its priority during times of resource contention, which is essential for protecting critical workloads from non-critical ones.
Properly setting these values is not just a matter of stability; it is a crucial technique for cost management in a cloud environment. Accurate requests allow cluster autoscalers to make intelligent decisions about when to add or remove worker nodes. Oversized requests waste money by forcing the cluster to provision more capacity than is truly needed, while undersized requests lead to stability issues and poor system performance. Therefore, tuning resource specifications is the baseline for efficient scheduling.
Technique Node Selectors and Node Affinity
Node Selectors are the simplest way to constrain a Pod to run on nodes with a specific label. By applying a label (e.g., `disk=ssd` or `gpu=true`) to a node and specifying that label in the Pod definition's `nodeSelector` field, the scheduler is restricted to choosing only those matching nodes. This is a hard constraint, meaning if no nodes match the selector, the Pod remains unscheduled. This technique is often used for simple segregation of workloads based on hardware type or licensing restrictions.
Node Affinity is the modern, more expressive successor to Node Selectors. It allows for soft or "preferred" rules in addition to hard or "required" rules. For example, an operator can specify that a Pod *must* run on an SSD node (`requiredDuringSchedulingIgnoredDuringExecution`), but *should* preferably run on a node in a specific availability zone (`preferredDuringSchedulingIgnoredDuringExecution`). The distinction between required and preferred rules provides far greater flexibility to the scheduler, allowing it to try to optimize placement while guaranteeing minimum requirements.
Using Node Affinity is vital for performance-sensitive applications, as it allows Pods to be placed onto servers with specific underlying characteristics, such as specialized networking or high-speed storage. It is also a key compliance tool, enabling teams to enforce sovereignty rules by ensuring that Pods containing sensitive data only land on nodes hosted in a specific region or data center. The "IgnoredDuringExecution" suffix means that if a node's labels change while a Pod is running, the Pod is not automatically evicted, but future scheduling decisions will respect the new labels.
Technique Taints and Tolerations
Taints and Tolerations work in opposition to Node Affinity; instead of attracting Pods, they repel them. A Taint is applied to a node and effectively marks that node as undesirable for scheduling. For a Pod to be placed on a Tainted node, the Pod must explicitly declare a matching Toleration in its specification. This mechanism is primarily used to reserve a set of nodes for specific, privileged, or licensed workloads, or to cordon off unhealthy nodes.
The power of Taints lies in their "effect" specification, which dictates what happens to a Pod that does not tolerate the taint. Common effects include `NoSchedule` (new Pods will not be scheduled on the node), `PreferNoSchedule` (the scheduler will try to avoid the node), and `NoExecute` (if a Pod is already running and a new taint is applied, the Pod will be evicted unless it tolerates the taint). The `NoExecute` effect is particularly useful for handling node conditions like memory pressure or network unavailability, automatically evicting Pods that cannot tolerate the poor environment.
A standard use case for Taints and Tolerations is separating control plane components from application workloads. Kubernetes control plane nodes often have Taints applied to ensure user-deployed Pods do not consume critical resources needed by the scheduler, API server, and etcd. Similarly, if a company has licensed database nodes, Tainting them ensures only the Pods with the corresponding license toleration can be scheduled there, providing strong segregation and license compliance. This technique is non-negotiable for large, multi-tenant clusters.
Comparison of Primary Placement Techniques
The three foundational placement techniques—Node Selectors, Node Affinity, and Taints/Tolerations—form the basis of all explicit scheduling control in Kubernetes. They each serve distinct purposes based on whether the goal is to enforce a hard requirement, express a preference, or actively repel workloads. Understanding their mechanisms and when to use each one is crucial for optimal Pod placement and cluster management. This comparison illustrates the core differences and intended use cases.
| Technique | Mechanism | Rule Type | Primary Use Case |
|---|---|---|---|
| Node Selector | Node must match Pod's label exactly. | Hard Constraint | Simple, mandatory hardware requirements (e.g., dedicated GPU nodes). |
| Node Affinity | Scheduler searches for matching node labels. | Hard (Required) or Soft (Preferred) | Fine-grained control, failure domain spreading, or preferred localization. |
| Taints and Tolerations | Node repels Pods unless the Pod has a matching toleration. | Hard Repulsion (NoSchedule) or Soft Repulsion (PreferNoSchedule) | Node reservation, dedicating nodes to specific tenants, or automatic eviction of Pods from failing nodes. |
Technique Pod Affinity and Anti-Affinity
While Node Affinity governs where a Pod lands relative to a node's properties, Pod Affinity and Anti-Affinity control where a Pod lands relative to *other Pods*. This is a critical technique for achieving service resilience, performance optimization, and fault isolation in a microservices environment. Pod Affinity is used to ensure that two Pods or groups of Pods are scheduled onto the same topology domain, such as the same node, rack, or availability zone.
Pod Anti-Affinity is often more frequently used than Affinity, as it ensures Pods are spread apart, minimizing the impact of a single point of failure. For example, if a team runs five replicas of a critical service, they can use Pod Anti-Affinity to ensure that no two replicas ever land on the same node, ensuring that the failure of one machine does not compromise the service's availability. Like Node Affinity, both Pod Affinity and Anti-Affinity support `requiredDuringScheduling` (hard) and `preferredDuringScheduling` (soft) variants, providing flexibility in enforcement.
Affinity is often used for performance optimization, particularly for Pods that communicate frequently and need low network latency, or for Pods that need to access shared local data. Anti-Affinity, however, is the cornerstone of high availability in Kubernetes. By distributing critical components, it forces the scheduler to prioritize fault tolerance. When combined with Topology Spread Constraints (discussed later), these affinity rules become the primary tools for distributing workloads across the cluster's physical and logical boundaries effectively.
Technique Priorities and Preemption
Priority and Preemption is a scheduling technique that allows operators to define an order of importance for workloads. In resource-constrained clusters, lower-priority Pods can be preempted (evicted) to make room for newly created, higher-priority Pods. This mechanism is essential for protecting mission-critical applications and ensuring they always receive the resources they need, even at the expense of less important, best-effort workloads.
The process starts by creating a PriorityClass resource, which defines a unique integer value for the priority. Pods then reference this PriorityClass in their specifications. When a high-priority Pod cannot be scheduled due to insufficient resources, the scheduler looks for nodes running lower-priority Pods that can be evicted. The lowest-priority Pods are chosen for eviction first, freeing up the required CPU and memory. This ensures that the cluster effectively manages its resources based on business importance, not just chronological arrival.
Preemption is a powerful but potentially disruptive tool. It is typically used to ensure that latency-sensitive components, such as API gateways or databases, are always prioritized over batch jobs, testing suites, or logging agents. While it prevents cluster resource starvation, careful implementation is necessary, as aggressive preemption can lead to a "priority inversion" problem where low-priority jobs are continuously started and immediately preempted, never finishing their work.
Technique Resource Quotas and Limit Ranges
Resource Quotas and Limit Ranges are administrative scheduling techniques enforced at the Namespace level, not on individual Pods. They are vital for multi-tenant environments to prevent a single team or application from monopolizing cluster resources, ensuring fair capacity sharing across all tenants in the cloud.
A Resource Quota defines a limit on the total resource consumption (CPU, memory, storage) or the total count of Kubernetes objects (Pods, Services, Deployments) that can exist within a specific Namespace. If a user attempts to deploy a workload that would exceed the allocated quota for that Namespace, the API server rejects the request. This provides hard boundaries for capacity planning and budget allocation, making cluster consumption predictable and manageable.
Limit Ranges, on the other hand, enforce default or minimum/maximum resource requests and limits for Pods created within a Namespace. If a developer forgets to specify requests and limits in their Pod manifest, the Limit Range ensures default values are applied, preventing the Pod from being assigned the lowest QoS class (BestEffort) and potentially suffering premature termination. By enforcing standardized resource definitions, Limit Ranges improve cluster stability and reduce the likelihood of resource-starvation issues caused by configuration oversight.
Technique Topology Spread Constraints
Topology Spread Constraints are an advanced technique that formalizes and generalizes the concept of Pod Anti-Affinity across definable topology domains. They allow operators to specify how their Pods should be distributed across failure domains like nodes, racks, regions, or availability zones, ensuring uniform distribution for high availability.
Instead of just checking a single node, this constraint checks the distribution ratio of Pods across specified topology zones. The operator defines a `maxSkew` value, which represents the maximum allowed difference in the count of Pods across any two topology domains. If a placement decision would violate this skew, the scheduler is blocked. This provides a more robust and quantitative way to enforce resilience compared to the simple binary rules of Pod Anti-Affinity.
This technique is essential for critical services that must remain available during the failure of an entire availability zone or rack. For example, setting the topology key to `topology.kubernetes.io/zone` with a `maxSkew` of 1 ensures that replicas are nearly perfectly balanced across zones. This prevents an unequal distribution where one zone holds the majority of replicas, creating a hidden single point of failure within the distributed architecture.
Technique Custom Schedulers and Descheduler
The Kubernetes default scheduler is general-purpose and highly optimized for most workloads, but some specialized environments, such as High-Performance Computing (HPC) or machine learning clusters, require more nuanced logic. Custom Schedulers, such as Volcano, allow teams to replace or augment the default scheduler with one tailored for specific scenarios, including gang scheduling (where a group of Pods must all start together) or advanced resource sharing policies.
The Descheduler is not a traditional scheduler; it is a mechanism that runs periodically to move Pods that have been sub-optimally placed *after* they have been scheduled. Over time, due to node additions, deletions, or various scheduling events, Pods can drift into non-optimal configurations (e.g., concentrated on a few nodes). The Descheduler applies policies to detect these imbalances (e.g., nodes that are too lightly or heavily utilized) and evicts Pods, allowing the default scheduler to re-place them correctly, ensuring long-term cluster optimization.
Technique DaemonSets and Quality of Service (QoS) Classes
DaemonSets are not a scheduling technique in the traditional sense, but they are a workload type that imposes an implicit scheduling constraint. A DaemonSet ensures that one copy of a Pod runs on *every* qualifying node in the cluster. This is essential for cluster-wide services like monitoring agents, log collectors, or network proxies that must be present on every operating system node to maintain cluster functionality. Operators typically use Node Selectors or Taints to define which nodes qualify for a DaemonSet Pod placement.
Quality of Service (QoS) Classes are the final enforcement layer for scheduling and, more importantly, runtime eviction. There are three QoS classes: Guaranteed, Burstable, and BestEffort. The class is determined by the Pod’s Request and Limit specifications. Guaranteed Pods (where requests equal limits for all containers) have the highest priority and are the last to be evicted. BestEffort Pods (no requests or limits specified) have the lowest priority and are the first to be killed when the node experiences resource pressure, protecting the stability of the high-priority services.
Conclusion Optimizing the Kubernetes System
The 12 techniques for Kubernetes job scheduling provide a sophisticated toolkit for managing containerized workloads in any environment, from bare metal to public cloud platforms running on various hypervisors. Effective scheduling is the cornerstone of a healthy cluster, dictating not only application performance and resilience but also the overall infrastructure cost. By moving beyond the simple automation of the default scheduler, operators gain granular control over resource allocation and workload separation.
The most robust scheduling strategies are built by combining these techniques: using Resource Requests and Limits to define QoS and enable efficient scaling, employing Taints/Tolerations to partition the cluster, and leveraging Pod/Node Affinity rules alongside Topology Spread Constraints to achieve high availability. The result is an execution environment that is predictable, cost-optimized, and resilient to failure. Mastering these techniques is not just about placing a container on a node; it is about tuning the entire Kubernetes orchestration engine to meet complex operational and business demands effectively.
Frequently Asked Questions
What is the primary role of the Kubernetes scheduler?
Its primary role is to select the most suitable worker node for a newly created Pod based on resource requirements and policies.
What is the difference between a request and a limit?
A request is the guaranteed minimum resource allocation, while a limit is the hard maximum consumption allowed for a Pod.
When should I use Node Selectors versus Node Affinity?
Use Node Selectors for simple, mandatory placement; use Node Affinity for complex, preferred, or soft constraints.
What does a Taint with a NoExecute effect do?
It means any Pod on that node without a matching toleration will be immediately evicted, often used for unhealthy nodes.
How does Pod Anti-Affinity improve resilience?
It ensures that replicas of a critical service are spread across different nodes or failure domains, minimizing service impact.
What is the purpose of a PriorityClass?
PriorityClass assigns an importance level to a Pod, determining which Pods should be evicted during resource contention.
What is the highest Quality of Service (QoS) class?
The Guaranteed QoS class is the highest, assigned when a Pod’s requests equal its limits for all containers.
What does a Resource Quota enforce?
A Resource Quota enforces limits on the total resources or object count that a specific Namespace can consume.
How do Limit Ranges improve stability?
They enforce default or maximum/minimum resource values, preventing improperly configured Pods from destabilizing the node.
What is the difference between an Affinity rule and a Taint?
Affinity is an attractive force pulling Pods to nodes; a Taint is a repulsive force pushing Pods away from nodes.
What is the main function of the Descheduler?
The Descheduler runs periodically to find and evict sub-optimally placed Pods, allowing the scheduler to re-place them better.
What is the benefit of using a custom scheduler like Volcano?
Custom schedulers allow for specialized logic, such as gang scheduling or machine learning workload-specific placement.
How do DaemonSets impact the scheduling process?
DaemonSets implicitly schedule one Pod per qualifying node, overriding the default scheduler's free-choice selection process.
What is the purpose of Topology Spread Constraints?
They ensure that Pods are evenly distributed across various defined zones, like racks or availability zones, for better fault tolerance.
How can scheduling help with licensing constraints?
Taints and Tolerations can be used to reserve specific licensed servers so only Pods with the corresponding toleration can be scheduled there.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0





![100+ Azure DevOps Interview Questions and Answers [Updated 2025]](https://www.devopstraininginstitute.com/blog/uploads/images/202509/image_140x98_68c40aa9a3834.jpg)






![Future Scope of DevOps Careers in Pune [Updated 2025]](https://www.devopstraininginstitute.com/blog/uploads/images/202510/image_140x98_68e3a84652312.jpg)


