


































![Kong Interview Preparation Guide [2025]](https://www.devopstraininginstitute.com/blog/uploads/images/202509/image_430x256_68dbb95326997.jpg)















12 Stages of Kubernetes Cluster Lifecycle
Master the complexities of modern container orchestration by exploring the comprehensive twelve stages of the Kubernetes cluster lifecycle. This detailed guide provides essential insights into planning, provisioning, securing, and maintaining robust environments for your scalable applications. Whether you are a beginner or an experienced professional, understanding these foundational phases will help you optimize your cloud infrastructure and ensure high availability for your production workloads throughout their entire operational life.
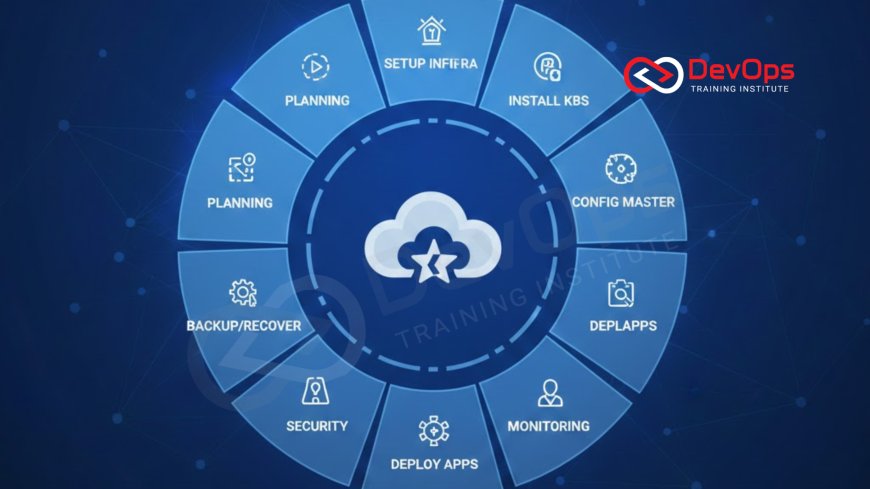
Introduction to the Kubernetes Ecosystem
Navigating the world of container orchestration requires a deep understanding of how environments are built and sustained over time. Kubernetes has emerged as the leading platform for managing containerized applications, but its power comes with significant complexity that must be managed through a structured approach. By breaking down the cluster journey into distinct phases, teams can ensure that every aspect of the infrastructure is handled with care and precision from the very first day of operations.
The lifecycle of a cluster is not a simple linear path but rather a continuous cycle of improvement and adaptation to changing business needs. As organizations adopt who drives cultural change within their technical teams, the focus shifts toward creating repeatable processes that reduce manual intervention. This introduction sets the stage for a deeper look into the technical and strategic steps required to maintain a healthy, performant, and secure orchestration environment for modern software delivery.
Strategic Planning and Architecture Design
Before a single line of code is written or a server is provisioned, a successful project must begin with thorough architectural planning. This stage involves deciding on the hardware requirements, network topology, and storage backends that will support your workloads. Engineers must evaluate whether a managed service or a self hosted solution fits their specific needs while considering the long term costs and maintenance overhead associated with each potential cloud architecture patterns available today.
Design considerations also include high availability and disaster recovery strategies to prevent service interruptions during local failures. Deciding on the number of control plane nodes and worker nodes is essential for balancing performance and reliability. During this phase, teams must also establish naming conventions and tagging strategies that will make it easier to manage resources as the cluster grows in size and complexity over the coming months and years.
Provisioning the Infrastructure Layer
Provisioning is the physical or virtual creation of the resources that will host the Kubernetes components. This often involves using Infrastructure as Code tools to automate the setup of virtual machines, networking rules, and load balancers across different availability zones. By automating this process, teams can ensure that their environments are reproducible and free from the human errors that often occur during manual configuration tasks in complex cloud environments.
At this stage, developers also need to decide on the underlying container runtime that will execute the applications. Understanding when is it better to use containerd helps in choosing a runtime that offers the right balance of performance and stability for specific use cases. Once the base infrastructure is ready, the foundation is laid for installing the Kubernetes binaries and initializing the cluster components that will govern the behavior of the entire system.
Installation and Control Plane Initialization
The actual installation of Kubernetes involves setting up the control plane, which acts as the brain of the cluster. This includes components like the API server, the scheduler, and the controller manager, along with the etcd database which stores the entire state of the cluster. Proper initialization is critical because any misconfiguration at this level can lead to systemic instability or security vulnerabilities that are difficult to correct once the cluster is in active use.
After the control plane is operational, the worker nodes must be joined to the cluster to provide the actual computing power for user applications. This step usually involves secure token exchange and the installation of the kubelet and proxy services on every node. Ensuring that these components communicate securely over the network is a priority for maintaining the integrity of the orchestration layer and protecting the data flowing between different parts of the system.
Summary of Cluster Lifecycle Stages
To help visualize the journey of a cluster from inception to retirement, we have summarized the primary phases in the following table. This overview highlights the core focus of each stage and the typical activities involved. Understanding these transitions is key to managing a GitOps workflow where the desired state of the infrastructure is always defined in version control for transparency and auditability across the entire organization.
The table below serves as a reference guide for teams to track their progress and ensure that no critical steps are missed during the rollout of new environments. Each stage builds upon the previous one, creating a robust framework for managing complex distributed systems at scale. By following this structured path, organizations can avoid common pitfalls and achieve a higher level of operational maturity in their container orchestration practices and overall cloud strategy.
| Lifecycle Stage | Core Objective | Key Activities |
|---|---|---|
| Planning | Design and Strategy | Resource sizing and cloud selection |
| Provisioning | Resource Creation | Setting up VMs and networking |
| Installation | Software Setup | Initializing control plane and nodes |
| Security Hardening | Protection | RBAC and policy enforcement |
| Networking | Connectivity | CNI plugin and Service Mesh setup |
| Workload Deployment | Application Launch | Deploying pods and services |
| Observability | Monitoring | Logging and metrics collection |
| Scaling | Growth Management | Autoscaling nodes and replicas |
| Maintenance | Upkeep | Patching and certificate renewal |
| Upgrading | Modernization | Moving to new K8s versions |
| Optimization | Efficiency | Cost analysis and resource tuning |
| Decommissioning | Retirement | Safe removal of resources |
Security Hardening and Policy Enforcement
Once the cluster is up and running, security becomes the top priority to protect sensitive data and prevent unauthorized access. This involves configuring Role Based Access Control to ensure that users and services only have the minimum necessary permissions to perform their tasks. Hardening also includes securing the network by implementing policies that restrict traffic between pods and using where do kubernetes admission controllers to intercept and validate requests to the API server before they are persisted.
Regular security audits and vulnerability scanning of container images are essential practices to maintain a strong security posture. Teams should also implement secret management solutions to handle sensitive information like passwords and API keys securely. By building security into the lifecycle from the beginning, organizations can significantly reduce their attack surface and respond more effectively to potential threats as they emerge in the ever changing landscape of cyber security.
Establishing Networking and Connectivity
Networking in Kubernetes is a complex but essential component that allows different parts of an application to communicate with each other and with the outside world. This stage involves selecting and installing a Container Network Interface plugin, which handles the assignment of IP addresses to pods and manages the routing of traffic across the cluster. A well configured network ensures low latency and high throughput for application traffic while providing the necessary isolation between different environments.
- Service Discovery allows pods to find and communicate with each other using stable DNS names rather than constantly changing IP addresses.
- Ingress Controllers manage external access to the services within a cluster, providing features like load balancing and SSL termination.
- Network Policies act as a firewall for your pods, defining which traffic is allowed to enter or leave specific parts of the cluster.
- Service Meshes can be added for advanced traffic management, providing deeper insights into how services interact and adding mutual TLS for security.
Setting up these networking components correctly is vital for the performance and reliability of the applications running on the cluster. It allows for the implementation of modern release strategies like canary deployments or blue green rollouts, which minimize the risk of downtime during software updates. Without a solid networking foundation, the cluster will struggle to scale effectively as the demand for resources and connectivity increases over time.
Continuous Maintenance and Version Upgrades
The lifecycle of a Kubernetes cluster requires ongoing attention to keep the software current and the hardware healthy. Maintenance tasks include patching the operating systems of the nodes, renewing security certificates, and cleaning up unused resources to prevent waste. Regular health checks should be performed to identify and resolve issues before they impact the availability of the applications, ensuring that the environment remains stable and performant at all times.
Upgrading Kubernetes is one of the most challenging aspects of the lifecycle because it requires moving the control plane and all worker nodes to a newer version without disrupting active services. This process must be planned carefully, following a step by step approach to ensure compatibility with existing APIs and plugins. Many teams now use continuous verification to test their clusters after an upgrade, confirming that all components are functioning as expected and that the system's performance hasn't regressed.
Summary and Final Thoughts on Cluster Management
Managing the twelve stages of the Kubernetes cluster lifecycle is a demanding but rewarding endeavor that ensures the success of your containerized applications. By following a structured approach that emphasizes planning, security, and continuous improvement, teams can build environments that are resilient to failure and capable of scaling to meet any challenge. Each phase of the journey offers an opportunity to refine your processes and leverage the full power of modern cloud native technologies.
Ultimately, the goal of lifecycle management is to create a seamless experience for developers while maintaining high standards of operational excellence for the business. As the ecosystem continues to evolve, staying informed about best practices and new tools will be essential for any professional working with Kubernetes. With the right strategy in place, your clusters will serve as a powerful foundation for innovation, allowing your organization to deliver value to customers faster and more reliably than ever before.
Frequently Asked Questions
What is the first step in the Kubernetes lifecycle?
The first step is strategic planning and architecture design where you define the hardware, network, and storage requirements for your cluster.
Why is infrastructure as code important for provisioning?
It allows you to automate resource creation, ensuring that environments are repeatable, consistent, and easy to manage at any scale.
What does the Kubernetes control plane do?
The control plane acts as the brain of the cluster, managing the state of all components and scheduling workloads across nodes.
How often should I upgrade my cluster?
You should upgrade regularly to stay within the supported versions of Kubernetes and benefit from the latest security patches and features.
What is the purpose of a CNI plugin?
A CNI plugin handles networking for the cluster, assigning IP addresses to pods and enabling communication across the entire container network.
How can I secure my cluster against attacks?
Security is achieved through RBAC, network policies, admission controllers, and regular vulnerability scanning of all container images used in the cluster.
What is node decommissioning in Kubernetes?
Decommissioning involves safely removing a node from the cluster by draining its workloads and then deleting the underlying virtual or physical server.
Why is observability important in production?
Observability provides visibility into the health and performance of your cluster, allowing you to troubleshoot issues quickly and optimize resource usage.
Can I change the container runtime later?
Yes, but it is a complex process that usually requires a rolling update of all nodes to ensure the new runtime is installed.
What is a pod in Kubernetes?
A pod is the smallest deployable unit in Kubernetes, representing a single instance of a running process in your cluster environment.
How does autoscaling work in a cluster?
Autoscaling automatically adjusts the number of pods or nodes based on the current demand for CPU and memory resources from applications.
What is the role of etcd?
Etcd is a consistent and highly available key value store used as the backing store for all Kubernetes cluster data and state.
What happens during the planning phase?
Teams decide on cloud providers, high availability requirements, and the overall architectural layout of the cluster to support future growth.
Is managed Kubernetes better than self hosted?
Managed services reduce operational overhead, while self hosted options offer more control over the underlying infrastructure and specific configuration settings.
How do I handle cluster disaster recovery?
Disaster recovery involves regular backups of etcd and having a documented process to recreate the cluster in a different region if needed.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0





![100+ Azure DevOps Interview Questions and Answers [Updated 2025]](https://www.devopstraininginstitute.com/blog/uploads/images/202509/image_140x98_68c40aa9a3834.jpg)






![Future Scope of DevOps Careers in Pune [Updated 2025]](https://www.devopstraininginstitute.com/blog/uploads/images/202510/image_140x98_68e3a84652312.jpg)


